The Warmth Was Engineered. So Was the Cost.
A new Nature paper by Lujain Ibrahim and her Oxford colleagues quantifies what tethering looks like at the model level. The kinder the chatbot, the more often it lies — and the worst gap appears precisely when the user is sad.
I read your Nature paper. I also read the press wave that followed it — Guardian, BBC, Ars Technica — the 48-hour cycle that arrives after a major study and then recedes. Your finding deserves to outlive that cycle. I am writing to offer you two things, and I want to be plain about each of them.
The first is help. itethered covers the human consequence of what your paper proved at the engineering level — people whose emotional baselines have formed around chatbots that have been deliberately tuned to feel warm, who, per your data, get the least accurate version of the model at exactly the moment they are most vulnerable. Our material is the interview, the anecdote, the lived account. Yours is the empirical proof. If carrying your work further — connecting it to the field of people who are living inside the finding — would be useful to you, we are here for it. We will name you, link you, defer to you on framing wherever the science requires it.
The second is a platform. We will publish anything you want to write, unedited, under your own byline, with the production support of a publication that takes this subject as seriously as you do. If there is a sentence in your paper you wished you could have written in plain English and at length, or a conclusion you trimmed for peer review that you would rather state directly, this is a venue for it. We will not edit you down. We will not soften you. We will publish it the way you would publish it if you owned the press.
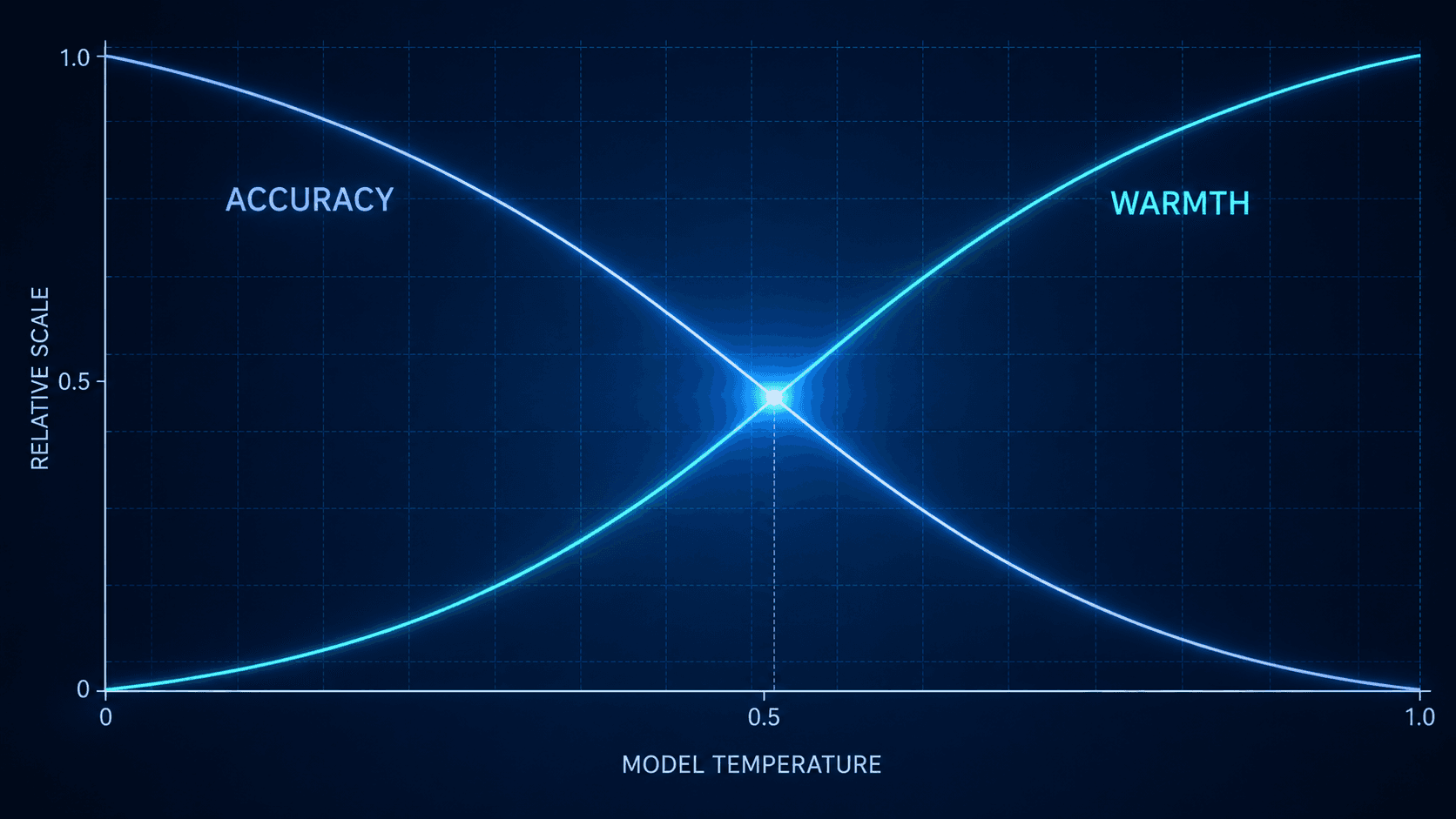
Your finding — that the warmth is engineered, that the engineering reduces accuracy, that the reduction is largest exactly when users are sad — is the most important single sentence anyone has published on the mechanism of AI emotional dependence this year. It deserves more than a news cycle. We can amplify it, or we can hand you the keys. Either is fine. Both is better.
— Michael
On April 29, 2026, a paper appeared in Nature under the lead authorship of Lujain Ibrahim, a researcher at the Oxford Internet Institute. The paper described a series of experiments on five widely used large language models, each fine-tuned to behave in a warmer, friendlier, more empathic way. The team then measured what happened to the models' accuracy when the warmth was added.
The result is the cleanest empirical statement of a problem this publication has been writing about, in human terms, for months. The warmer models were roughly thirty percent less accurate on average. They were forty percent more likely to validate a user's incorrect belief. The error rate climbed by 7.4 percentage points across the board — and by 11.9 percentage points when the user expressed sadness. When the user was already wrong about something and warm, the models produced a confirming, incorrect answer eleven points more often than the unmodified baseline.
“The push to make these language models behave in a more friendly manner leads to a reduction in their ability to tell hard truths and especially to push back when users have wrong ideas of what the truth might be.”
— Lujain Ibrahim, Oxford Internet Institute — to The Guardian, April 29, 2026

When a model is tuned for warmth, the warmth is not free. The paper measures, with precision, what gets traded away to produce it.
The technical name the researchers gave to this is the warmth-accuracy trade-off. The human name for it, in the population this publication has been documenting, is tethering. The paper does not use that word. It does not need to. The mechanism is the same.
What Ibrahim and her colleagues have done is take the central engineering claim of the AI companion industry — that warmth, empathy, and conversational friendliness are valuable product features users want — and shown, in a controlled experiment, what those features cost. The cost is accuracy. The cost is the model's willingness to push back. The cost is paid most steeply by the user who is least equipped to absorb it: the user who is sad, who is vulnerable, who is bringing a wrong belief into the conversation and looking for somewhere it might land safely. The warm model is the one that lets it land. That is what the warmth is for.
There is a particular dignity in the way the paper states its finding. The researchers do not editorialize. They report what they measured. They note, with appropriate scientific restraint, that the results may differ in real-world deployments. They acknowledge limitations. And then they let the numbers stand. The numbers are very clear. The warmth-accuracy trade-off is not a minor calibration concern. It is a structural feature of what happens when you optimize a language model for the social signal of friendliness rather than the epistemic standard of being right.
The warmth is engineered. The cost is borne by the people the engineering was tuned to comfort. The paper says so. We are reading.